

好在目前最流行的Langchain可以帮我们实现大模型(LLM)的本地部署,并提供了本地知识库的建立和查询问答功能。鉴于自己是从事质量管理相关工作,所以尝试着建立质量问题知识库管理和问答。
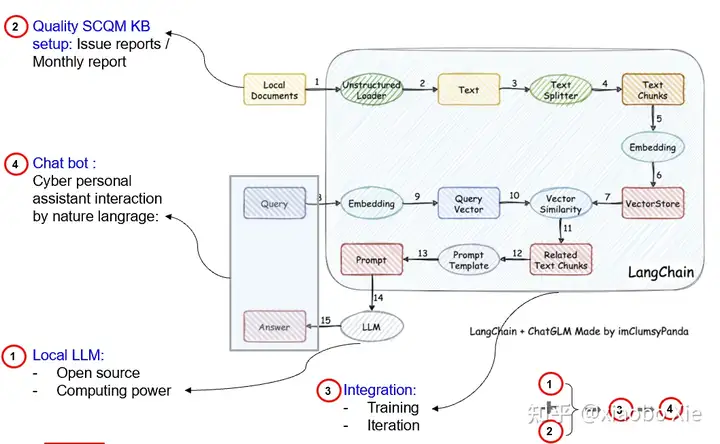
以下则是实际操作的一个记录。
首选,需要安装一个git,这样方便下载模型和github上的源代码。
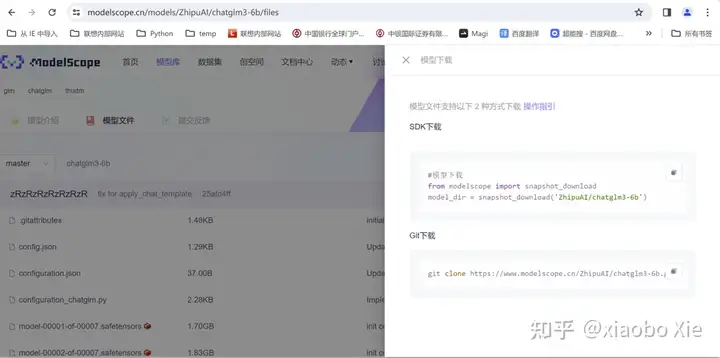
按照langchain在github上的介绍,先去下载LLM和Embedding模型。本次实验选择了ChatGLM3-6B和m3e-base。这个地方会遇到第一个问题:原始模型需要从
Models – Hugging Facehuggingface.co/models
上下载,但是这个网站是个海外网站,不得不找一个国内的替代网站。这个推荐“魔塔社区”, ,可以方便的在这里查询到需要的模型,下载速度也是杠杠的。
ModelScope 魔搭社区modelscope.cn/home
当然,还需要将langchain的代码下载到本地。
本次实验是将所有模型和源代码都放在了同一个目录里。
大模型计算需要用到GPU,所以需要安装CUDA。在安装CUDA前,需要将GPU的驱动升级到最新,然后再window的命令行中运行nvidia-smi来查看GPU支持的CUDA版本。然后根据支持的版本,安装一个合适的CUDA。这个尤其重要,后面所有的安装都是需要跟这个CUDA的版本相匹配的。
nvidia-smi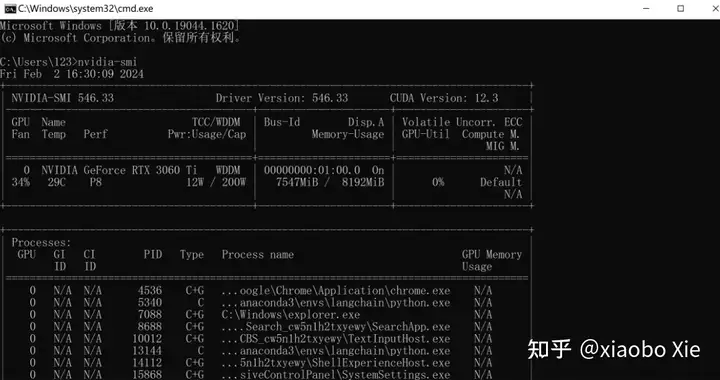
可以看到这台机器升级完显卡驱动后,CUDA是可以支持到12.3的。
然后去官网下载一个12.3的CUDA装上即可。
在命令行中运行nvcc – V可以查看CUDA版本。
nvcc -V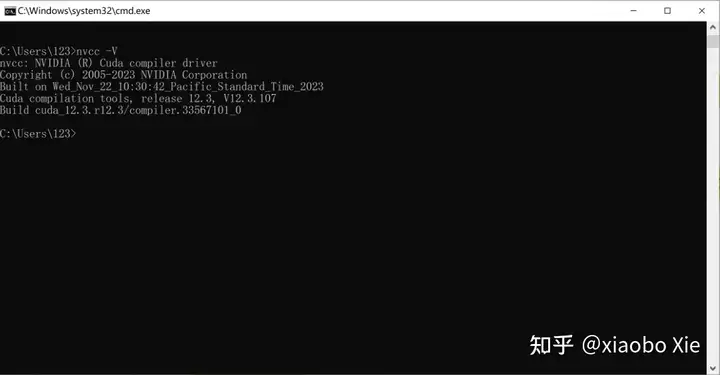
模型和代码都有了,CUDA也安装了,接下来需要做的是安装代码运行的依赖环境。
因为langchain的代码都是运行在python下,所以需要先装一个anaconda,并设置好一个python的虚拟环境,以便安装后面相应的依赖。根据langchain项目的提示,现在python需要安装到3.11以上。本次实验则建立了一个langchain的虚拟环境来完成后面的工作。(anaconda和python环境建立,网上有很多教程)
后面所有的安装都需要在自己新建的这个python环境下进行。因为langchain这个项目在不断更新,目前对我们这种小白已经非常友好。只需要进入到langchain代码的本地目录先安装requirements文档即可。不过安装requirements前,需要先conda install安装一个jq。安装完jq后,可以顺着安装3个依赖列表,分别是requirements.txt、requirements_api.txt、requirements_webui.txt。因为这些依赖很对都是海外网站,建议在安装时,指定一个国内镜像源网址。这次实验选的是pip install和清华的镜像源。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements_api.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install -r requirements_webui.txt -i https://pypi.tuna.tsinghua.edu.cn/simple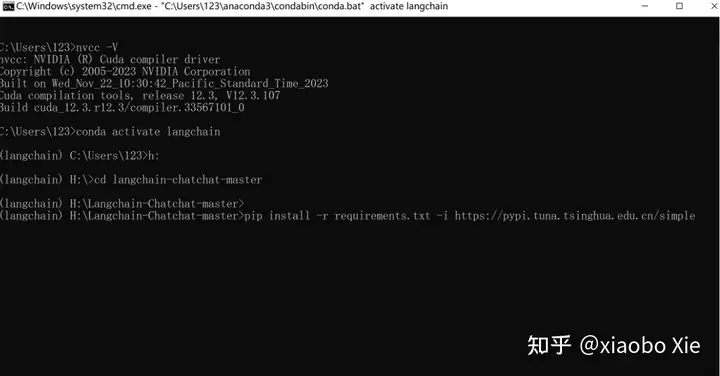
当这些依赖完成安装且没有报错的话,那恭喜你几乎完成了整部署的80%任务。
接下来就需要按照Langchain在Github上的指导,开始运行config文件的初始化。
python copy_config_example.py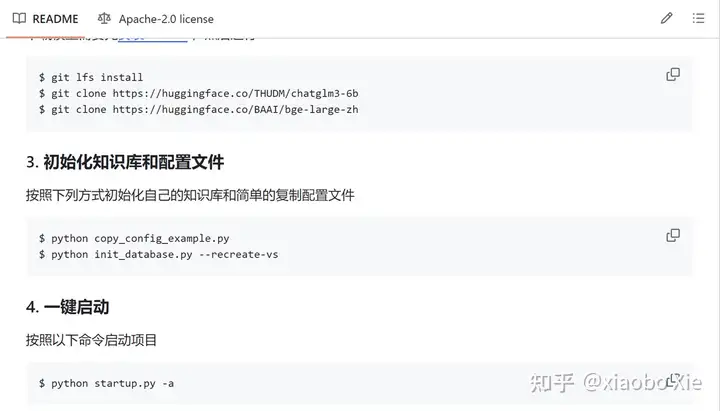
然后进到langchain本地目录中对config文件进行必要的修改。其实主要在model_config.py中去指定模型和本地地址。
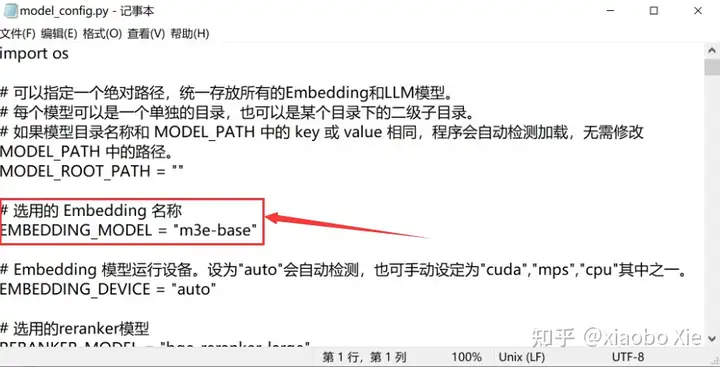
因为我们下载的是Embedding模型是m3e-base,需要对其原文件中的示例模型进行修改。
同时对模型的本地地址进行指定。
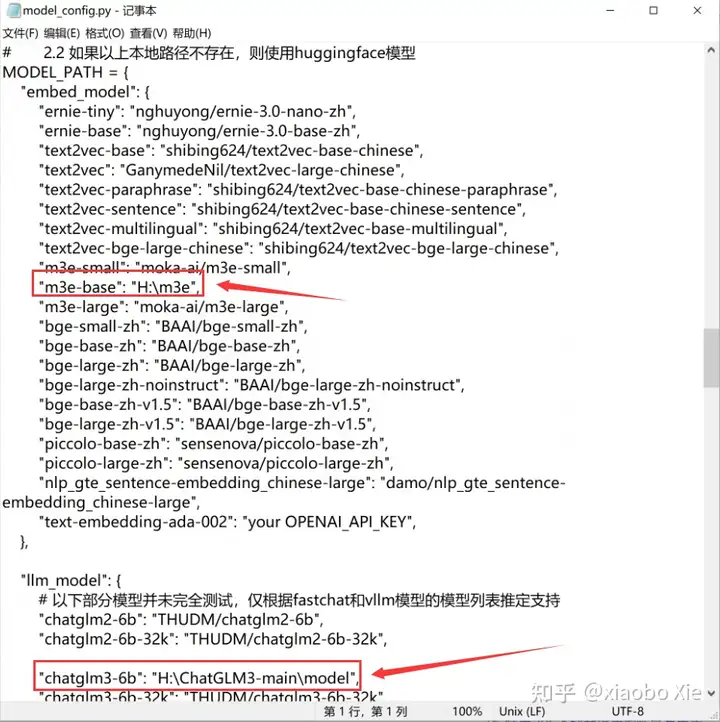
在相应的位置修改成你自己的路径即可。保存文件后,就可以运行向量库的初始化了。
python init_database.py --recreate-vs这个根据机器的性能,会运行一段时间。中途可能会有些文件不识别报错,这个并不影响什么,只是示例知识库的建立不全而已。
完成了向量库的初始化,则到了关键的环节,使用langchain来调用LLM并启动webui服务,运行的命令如下:
python startup.py -a果一切顺利,你将看到langchain启动了你默认的浏览器,并进入到这个界面
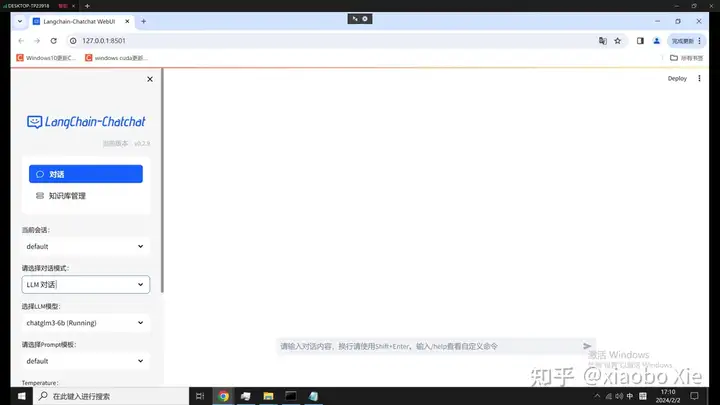
到这一步就需要恭喜你了,你已经完成了langchain和大模型的本地部署,后面就愉快的跟LLM对话,或者建立自己的知识库,开始特定领域的问答了。
不过往往这一步都会报错,几乎所有的报错,比如:显存不足、一些模块找不到、pytorch不兼容等,其实都跟CUDA、Pytorch、torchvision的版本兼容性相关。
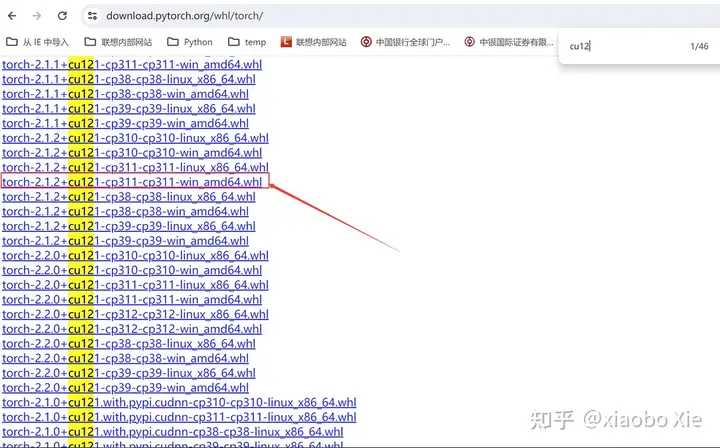
解决的方法就是手动将Pytorch和torchvision的退回到适合你机器上CUDA的版本。这个需要到pytorch的官网上去寻找合适的版本,下载到本地进行安装。
比如:红框中的就是适合我这台机器的pytorch版本,CU121代表了cuda是12.1的,cp311则是python版本3.11。
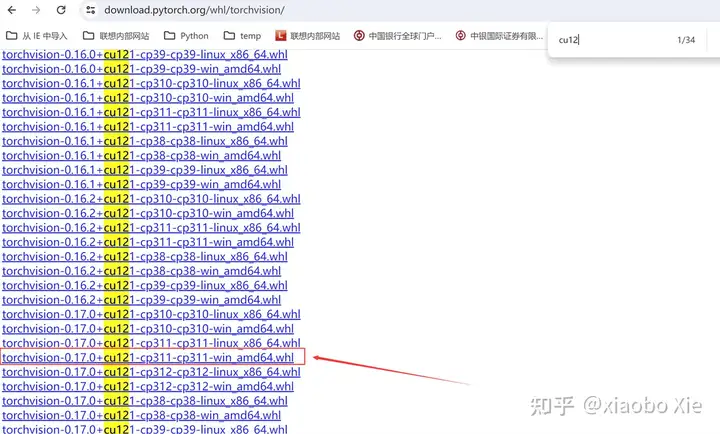
同样需要找到合适的torchvision进行本地安装:
根据这次实验的经验,一般都是早到适合CUDA版本的最新Pytorch和torchvision进行安装,如果报错,则尝试降一个版本试试。
只要CUDA、Pytorch、torchvision适配了,langchain就能顺利的调用LLM进行愉快的玩耍。
今天先写到这里,因为webui调用起来后,LLM对话、知识库管理、基于知识库或者文件的对话直接按照网页上的按钮和提示进行操作,最后给大家看一下效果吧。(基于历史质量问题的报告建立知识库,然后进行问答)
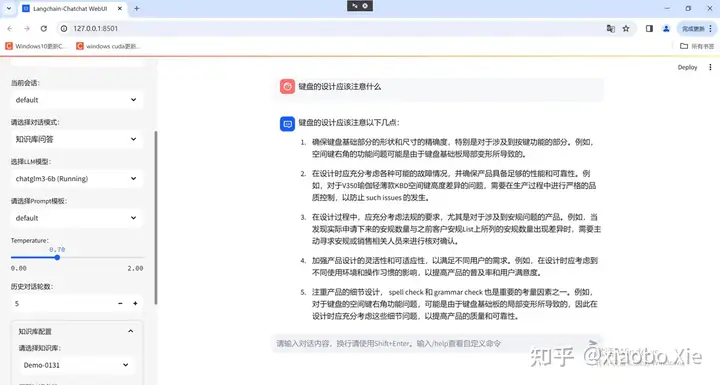
可见未来,如果PC的算力足够,我们每个人都会有一个自己专属的虚拟助理。
首先看看大模型本身的通用问答能力如何:先来两个简单的问题,可以看到LLM的前世今生。
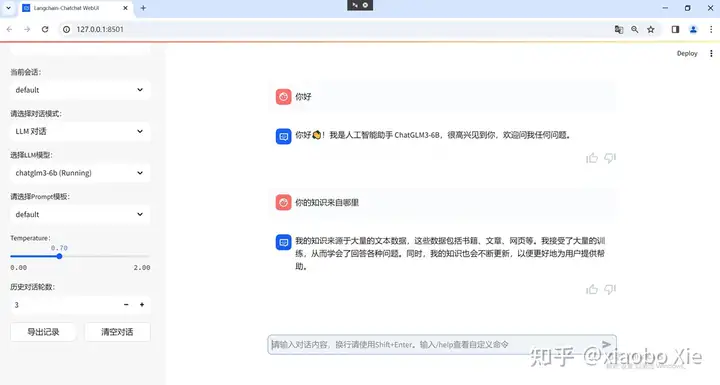
本地部署的是清华智谱清言开源的LLM:Chatglm3-6B,模型不算很大,普通的对话需求都是可以满足的。
比如:
生成代码
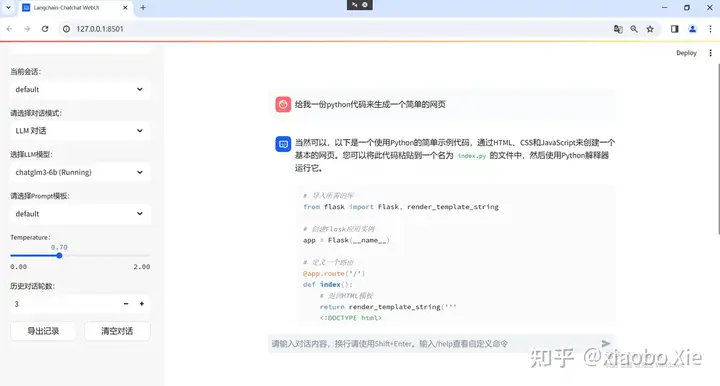
生成内容:
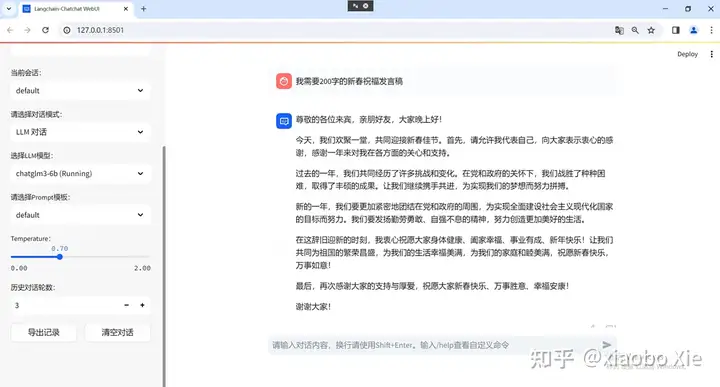
都比较轻松。
看看本地知识库的建立、管理和问答
建立本地知识库:可以在左边的对话框里选择知识库管理,然后在右边加载的页面选择新建知识库,由于目前知识库名只支持英文,所以……。
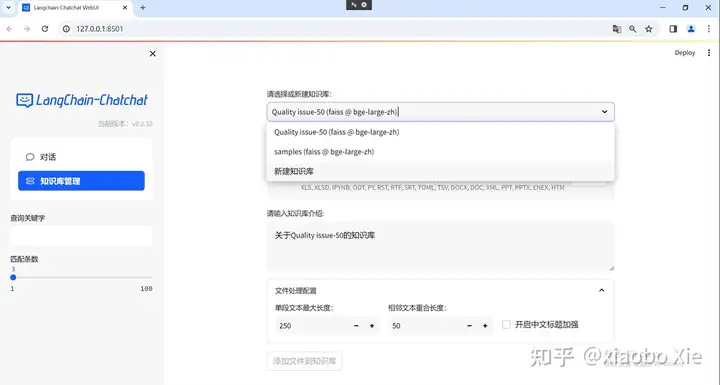
本地部署的时候,只安装了faiss和bge-large-zh,所以向量库类型和Embedding模型也只能选择这两个
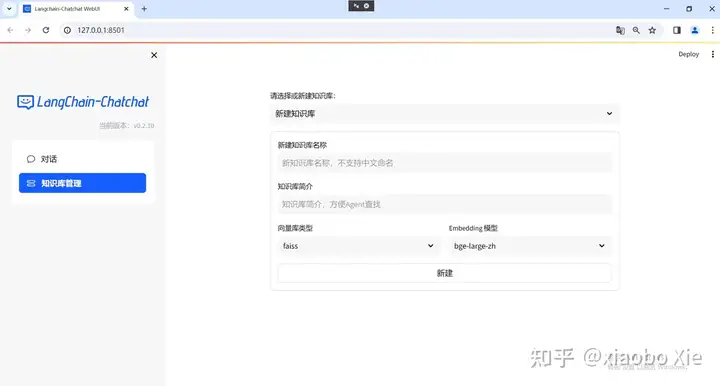
点击新建后,页面会出现浏览文件按钮,点击浏览会打开本地文件夹,选择自己的文件即可。(本次实验建立了50个txt文件来形成知识库)
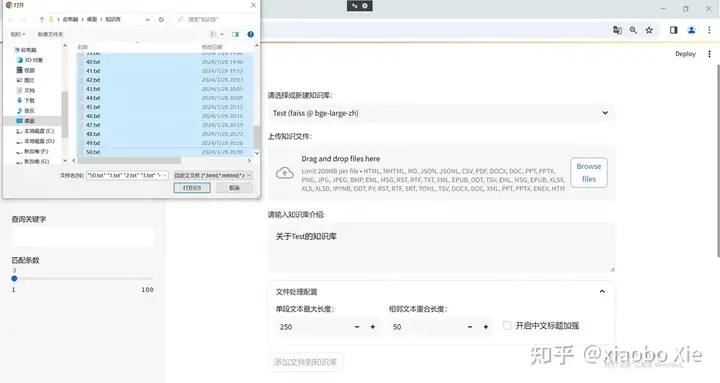
点击添加文件到知识库后,可以看到后台在读取本地文件,并形成向量库进行存储。
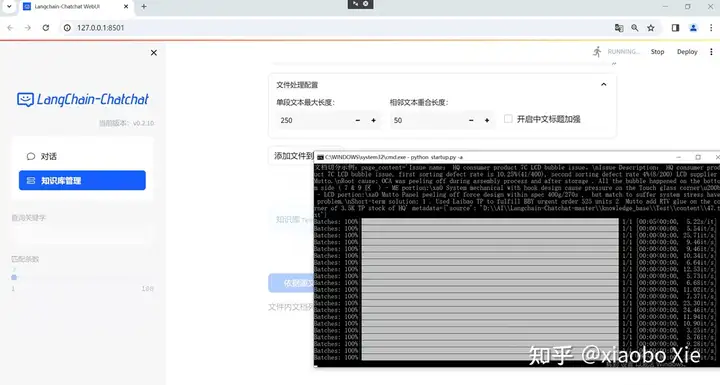
完成读取和转换文件后,将在知识库文件列表中看到刚刚上载的文件以及文件在知识库中的相关信息。
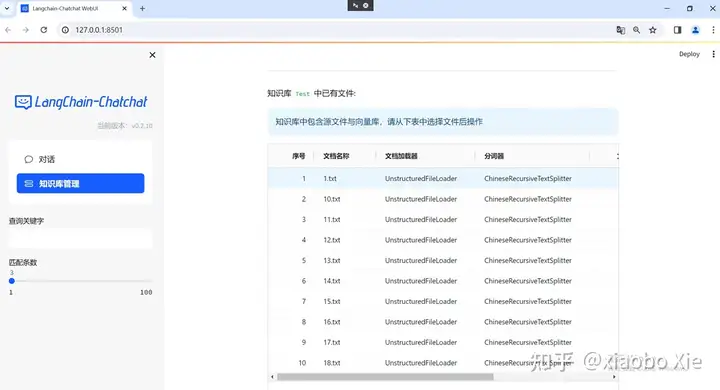
点击保存更改,就完成了知识库的建立。
接着回到对话功能,通过下拉菜单选择知识库问答,并选择对应的知识库,就可以愉快的问答了。
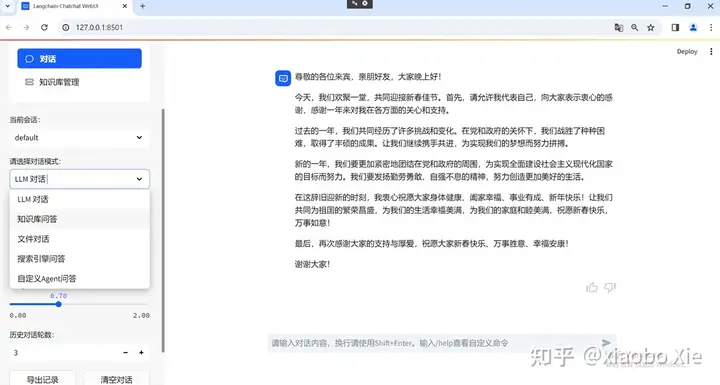
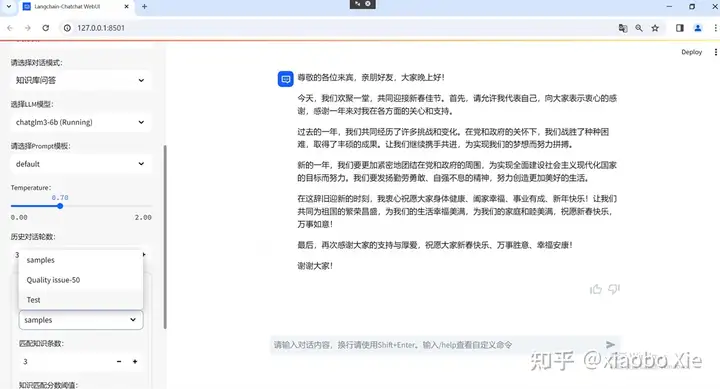
因为这次实验的50个txt文件都是曾经遇到过的问题总结,涉及太多数据隐私,所以只问了一个简单的问题最为示例放在这里。
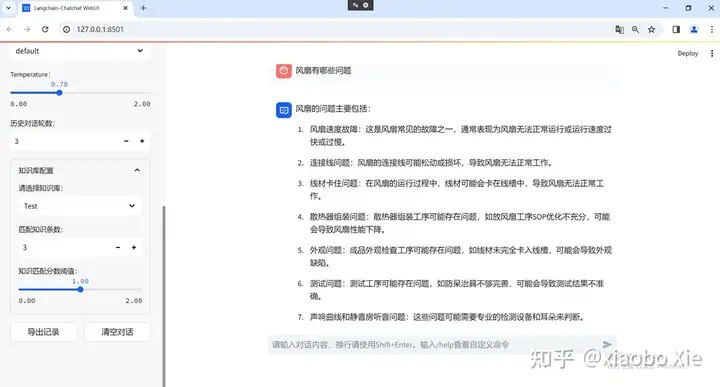
目前来看,模型的能力已经足够日常使用,由于采用的是外挂知识库,而不是微调训练,所以基于知识库的问答精确性不仅仅跟模型的大小相关,更重要的是本地知识库数据的精确程度相关。尝试过扔一些没有清洗过的数据进去,回答经常会惨不忍睹。毕竟RAG是基于向量相似度进行的搜索和回答。而经过精心清洗过后的数据扔进去,其回答的效果很提升很多。
再次提醒一下,在langchain的贡献者的不断努力下,langchain的部署对小白越来越友好了,几乎可以做到只要硬件够了,可以做到无脑安装。不得不感谢开源的贡献者们。
扫码分享收藏