
pandas_profiling :教你一行代码生成数据分析报告
By Vincent. @2021.4.14

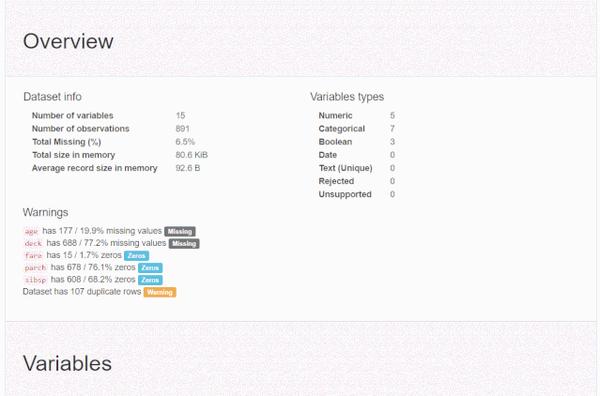
分析报告全貌
什么是探索性数据分析
熟悉pandas的童鞋估计都知道pandas的describe()和info()函数,用来查看数据的整体情况,比如平均值、标准差之类,就是所谓的探索性数据分析-EDA。
pandas_profiling简介
如果你想更方便快捷地了解数据的全貌,泣血推荐一个python库:pandas_profiling,这个库只需要一行代码就可以生成数据EDA报告。
pandas_profiling基于pandas的DataFrame数据类型,可以简单快速地进行探索性数据分析。
对于数据集的每一列,pandas_profiling会提供以下统计信息:
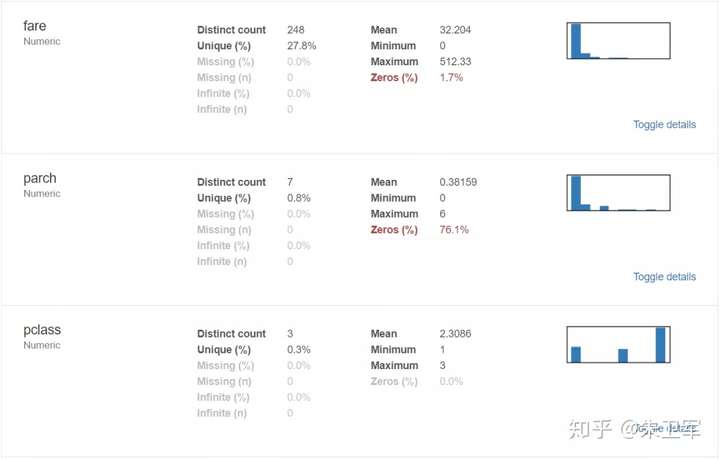
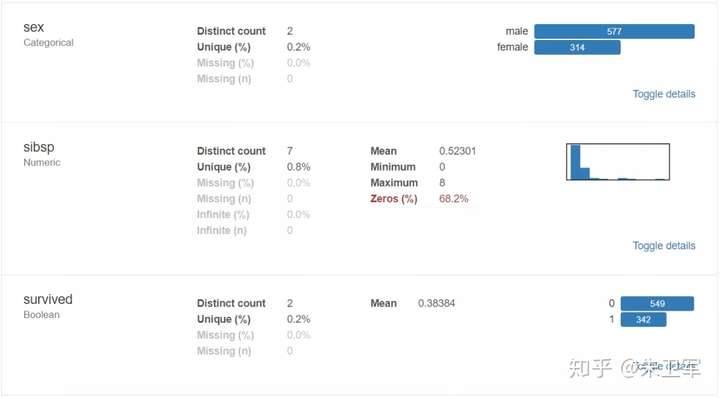
1、概要:数据类型,唯一值,缺失值,内存大小
2、分位数统计:最小值、最大值、中位数、Q1、Q3、最大值,值域,四分位
3、描述性统计:均值、众数、标准差、绝对中位差、变异系数、峰值、偏度系数
4、最频繁出现的值,直方图/柱状图
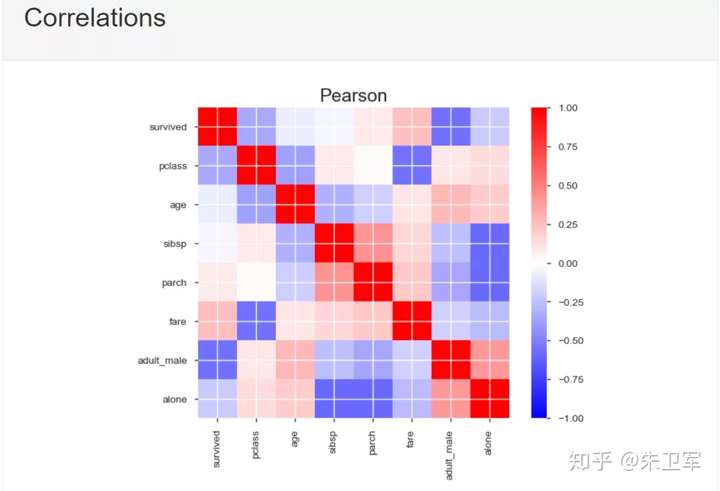
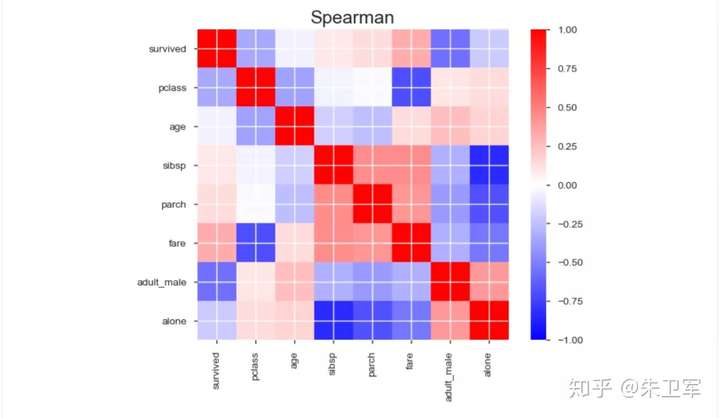
5、相关性分析可视化:突出强相关的变量,Spearman, Pearson矩阵相关性色阶图
并且这个报告可以导出为HTML,非常方便查看。
pandas_profiling安装
安装pandas_profiling可以使用pip、conda或者下载文件安装,非常方便。
我这里使用pip方式,在命令行输入:
pip install pandas-profiling本文在Jupyter notebook中进行代码实验。
pandas_profiling使用方法
1、加载数据集
我这里用经典的泰坦尼克数据集:
# 导入相关库
import seaborn as sns
import pandas as pd
import pandas_profiling as pp
import matplotlib.pyplot as plt
# 加载泰坦尼克数据集
data = sns.load_dataset('titanic')
data.head()输出:

2、使用pandas_profiling生成数据探索报告
report = pp.ProfileReport(data)
report输出报告:
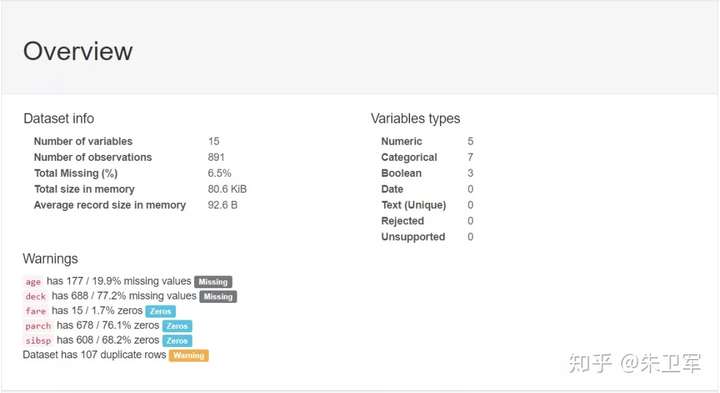
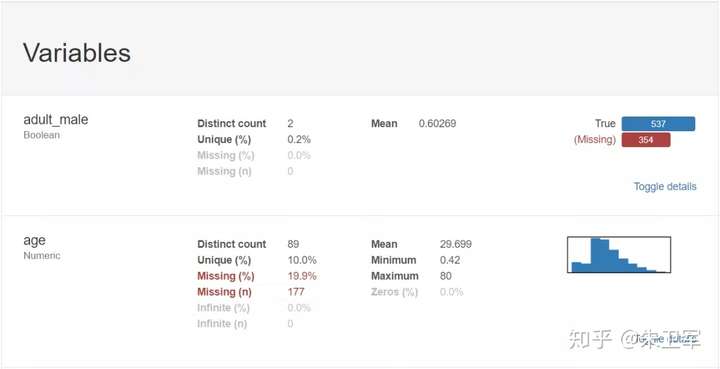

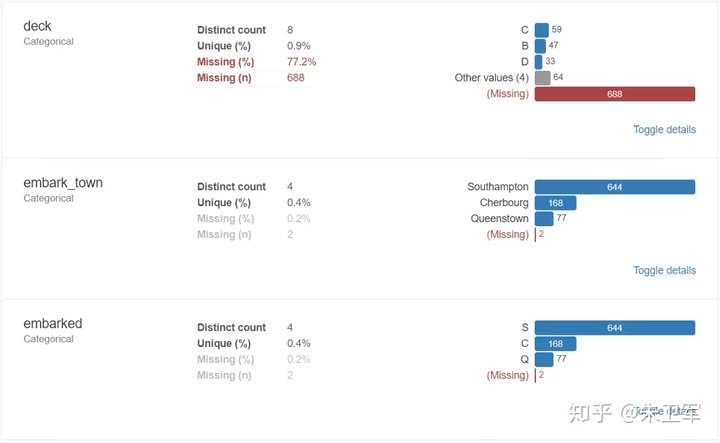

3、导出为html文件
report.to_file('report.html')总结
pandas_profiling可以用一行代码生成详细的数据分析报告,与pandas深度结合,非常适合前期的数据探索阶段,以及结果数据报告批量化生产。对不太熟悉python数据分析的新手来说,这是一个非常好用的工具。
扫码分享收藏